







Only 1 in 5 AI projects meet their KPIs. The model isn’t the reason.
Only 1 in 5 AI projects meet their KPIs. The model isn’t the reason.
This is Blog 4 in our Data Trust + AI Success Series
- Why seeing AI risk isn’t enough to protect you from it
- Security by obscurity just died. AI killed it.
- Why AI doesn’t behave like a human
- Why most AI projects are failing
- Why CISOs need a seat at the AI design table
- Why AI is a stress test of your security fundamentals
- How high data trust speeds up AI
- What are the minimum viable security controls for AI?
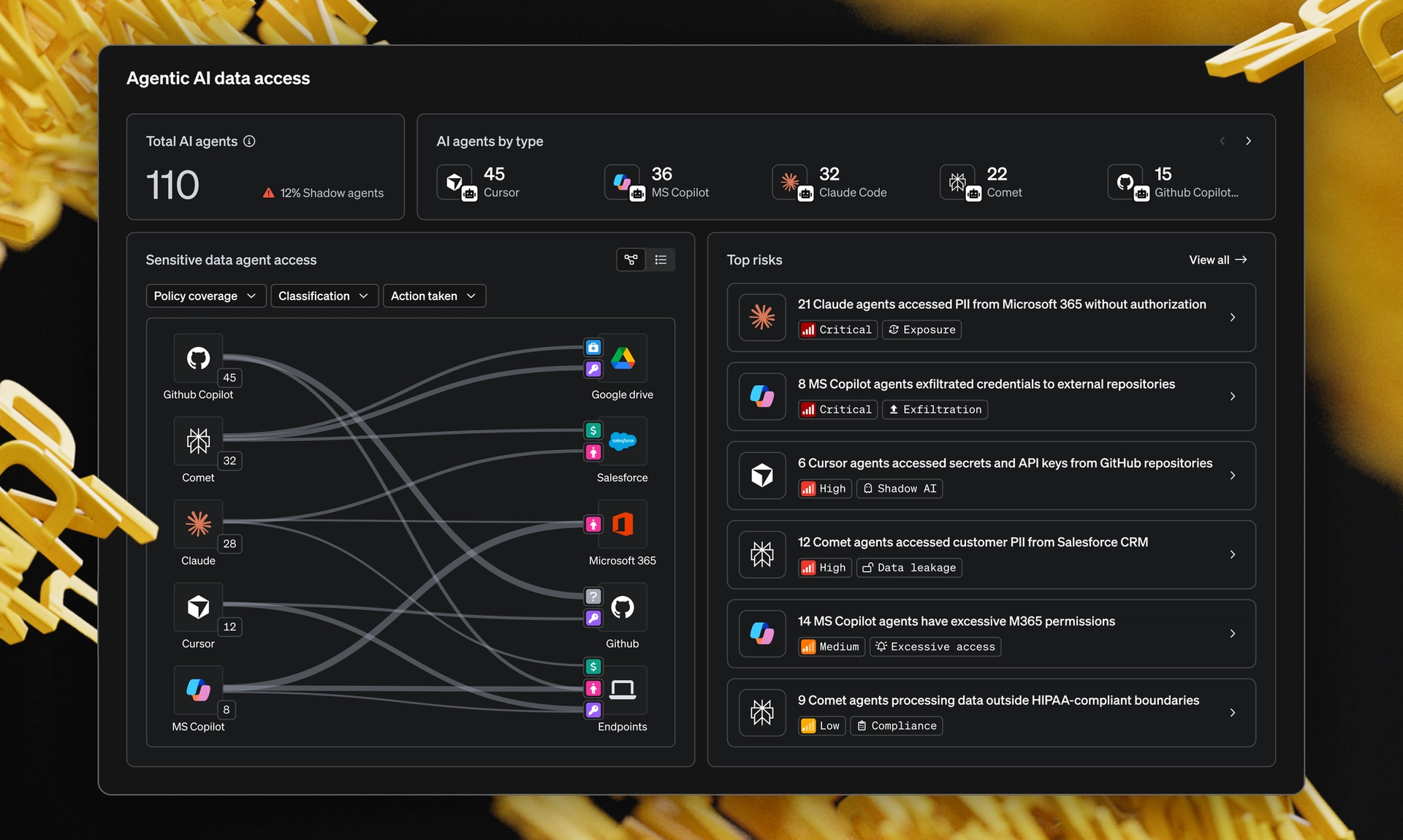
One finding from MIND’s research, The Impact of Data Trust on AI Success, is hard to look past. Out of every five AI initiatives at the enterprises in the study, only one was meeting its KPIs. The other four were being re-architected, paused or quietly walked back.
When the CISOs in the research opened the hood on those failed projects, they kept finding the same thing underneath. It wasn’t the model. It was the data.
What matters: AI projects rarely fail because the algorithms are flawed. They fail because the data feeding those algorithms was never classified or trusted in the first place.
Why are 4 in 5 AI projects missing their KPIs?
The same root cause kept surfacing. Data debt. Incomplete classification. Unscanned storage. Ungoverned access. The conditions that were survivable in a pre-AI world become the conditions that quietly break AI initiatives.

The survey data confirms what Igor described.

When the foundation is that shaky, the model on top of it doesn’t get a fair chance.
What does this look like inside a real organization?
One company in the research launched eleven AI initiatives over the past year. Two met their KPIs. The other nine were stalled or quietly walked back. In every one of those nine, data quality and known governance gaps were named as contributing factors.
That isn’t an AI problem, it has more to do with the data foundation.
The pattern is consistent. Teams scope a use case, connect the model to an existing data source and assume the data underneath is in a state that can support a reliable output. It usually isn’t. The repository was never fully classified. Access permissions were inherited from a SharePoint cleanup that never finished. The source data has duplicates, missing fields and rows nobody can vouch for. The model does exactly what it was asked to do, and the output is unusable.
What does AI project success actually require?
A different starting point. Before prompts, tokens or accuracy can be measured, security teams need to know what data the AI tool is reaching, whether that data has been classified and whether the access controls around it were built for the actor now using them.
This is where MIND focuses. MIND isn’t just inventorying data sources. It’s minding the foundation underneath every AI project the business is racing to ship, so the model on top of it has a chance of producing something the business can actually use. That means classifying what AI tools can reach, surfacing the ungoverned data that teams haven’t catalogued yet and giving security a clear line of sight from the data the model is consuming to the outputs it’s producing.
Organizations that treat data trust as a prerequisite for AI deployment approach the problem differently. They define the data quality standards their use case requires, measure whether those standards are being met and keep the visibility needed to connect a poor outcome to its actual cause. The result is an AI program where the failures show up early, while there’s still time to fix them, instead of late, when the budget is already gone.
Where do CISOs go from here?
This is one finding from a larger pattern in the research. The full report walks through all seven insights, with direct CISO quotes and a clear set of recommendations for security leaders trying to make AI projects succeed without giving up on governance.
Read The Impact of Data Trust on AI Success to see why most AI projects are missing their KPIs and what the organizations getting it right are doing differently.


