







Before AI, poor data governance used to be survivable.
Before AI, poor data governance used to be survivable.
This is Blog 2 in our Data Trust + AI Success Series
- Why seeing AI risk isn’t enough to protect you from it
- Security by obscurity just died. AI killed it.
- Why AI doesn’t behave like a human
- Why most AI projects are failing
- Why CISOs need a seat at the AI design table
- Why AI is a stress test of your security fundamentals
- How high data trust speeds up AI
- What are the minimum viable security controls for AI?
For years, you could get away with poor data governance. Files sat unclassified in SharePoint. Repositories got overshared. Data estates sprawled ungoverned. And nothing bad happened.
Why? Because no system went looking for everything. The unclassified files stayed hidden. The overshared repos went unnoticed. Years of accumulated data debt remained invisible behind a protective shield of obscurity.
AI just ripped that shield away.
What was actually protecting you all this time?
Security by obscurity kept you safe when your data catalog had gaps. If no tool could see all the data at once, the consequences of poor classification were limited. A human might stumble across something they shouldn't see, but they couldn't systematically surface every sensitive file across the entire estate.
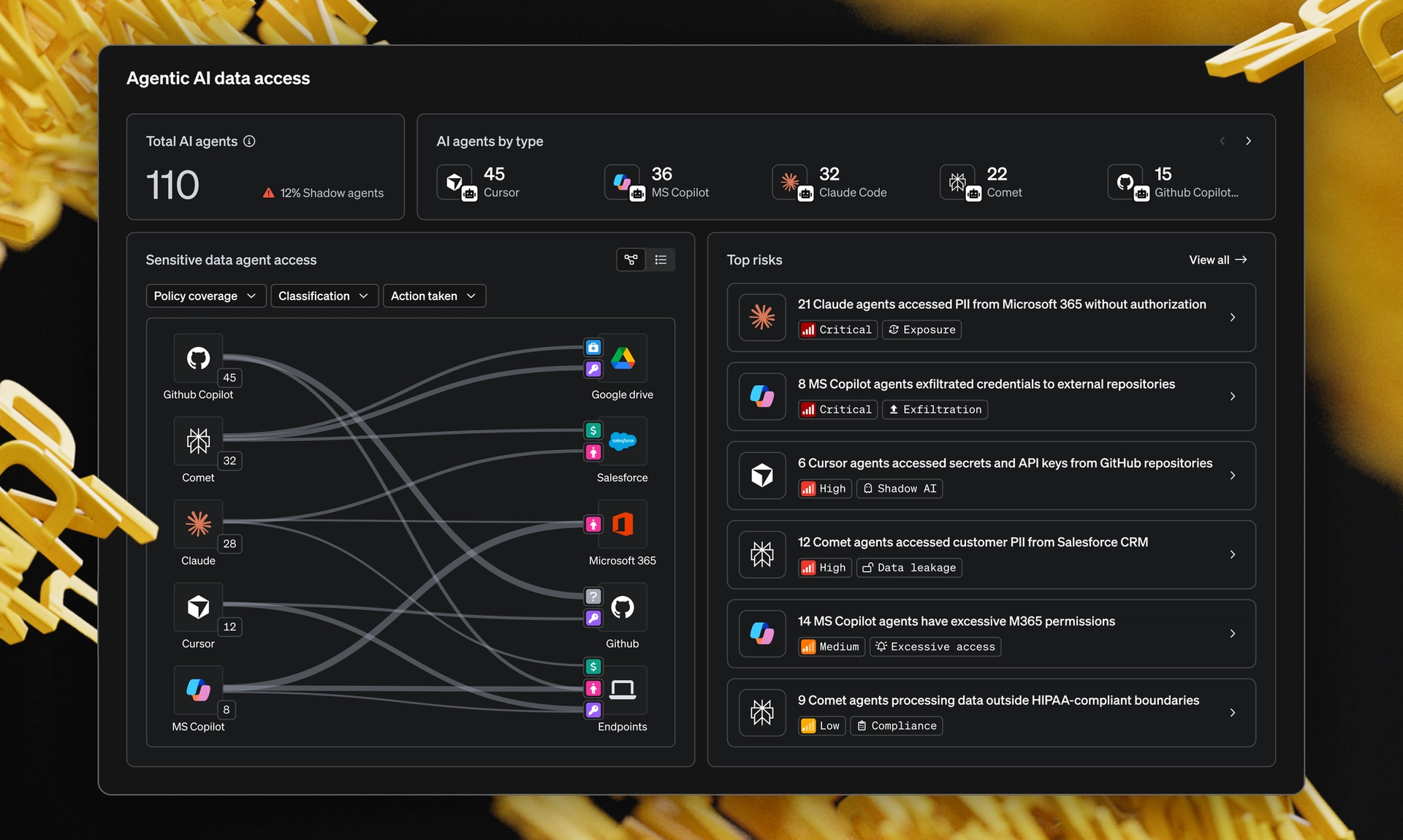
AI eliminates that backstop entirely. The moment an AI tool connects to a data source, it finds everything at scale, without direction, without judgment, without the natural filters a human would apply.
According to our research with CISO ExecNet:


What does this look like in practice?
AI exposes years of data debt the moment it connects. Here's what that means for real organizations.
At a large healthcare organization, three AI projects stalled during the pilot phase. In each case, the stated reason was incomplete data, inconsistent formatting and missing source lineage. The AI didn't create these problems. It exposed them.
At a manufacturing company, executive compensation files had been stored in SharePoint for years with no classification or access controls. When an Enterprise AI tool was deployed, those files were suddenly broadly accessible to a wide internal audience. Nobody intended for this to happen, but the AI found what was there.
Why can't you just fix this in a sprint?
This isn't a technical problem you can sprint away from. Years of accumulated data sprawl can't be resolved in a single sprint. But the urgency is real.
Every day an AI tool operates against an unclassified, ungoverned data estate, it's surfacing exposure that no one can see and no one is managing. And with 90% of enterprises now running Enterprise GenAI at scale, that exposure is multiplying faster than governance teams can respond.
What does this mean for your organization?
This isn't about whether your organization will adopt AI. The data clearly shows you already have. The question is whether the foundation beneath it can be trusted.
The security by obscurity that protected organizations from their own data debt for years is gone. AI made everything visible. Now every unclassified file, every overshared repository, every piece of ungoverned data is accessible at machine speed to systems that don't apply human judgment about what they should or shouldn't surface.
Where do you start?
The winners in the AI era treat data trust as a prerequisite, not an afterthought. They're investing in:
- Comprehensive data classification. You can't enforce policy on data you haven't classified.
- Data discovery at scale. Building a complete inventory of what data exists and where it lives.
- Governance that covers AI. Extending existing frameworks to include non-human actors.
- Visibility into data flows. Understanding what data AI tools can actually access.

The bottom line
Security by obscurity is dead. AI killed it.
Now the question facing every organization is, “Will you build the data trust foundation that allows you to move fast with AI?” Or will you continue carrying years of data debt into an environment that makes every single piece of it visible?
The organizations making that investment now are building the only foundation that lets them adopt AI at scale with any real confidence. Learn more about the role data trust plays in your AI successt
Data Trust + AI Success Blog Series
- Why seeing AI risk isn’t enough to protect you from it
- Security by obscurity just died. AI killed it.
- Why AI doesn’t behave like a human
- Why most AI projects are failing


