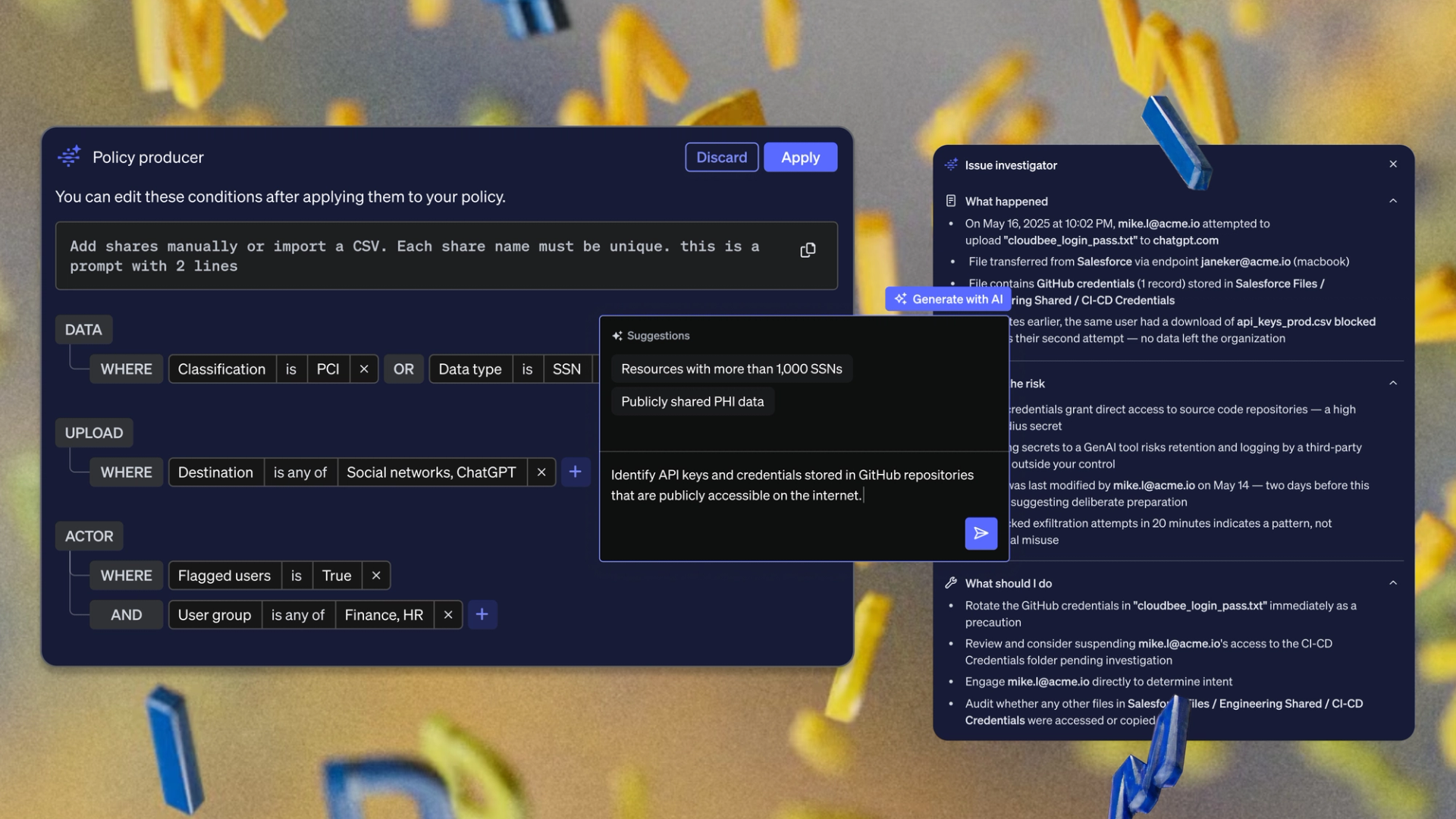







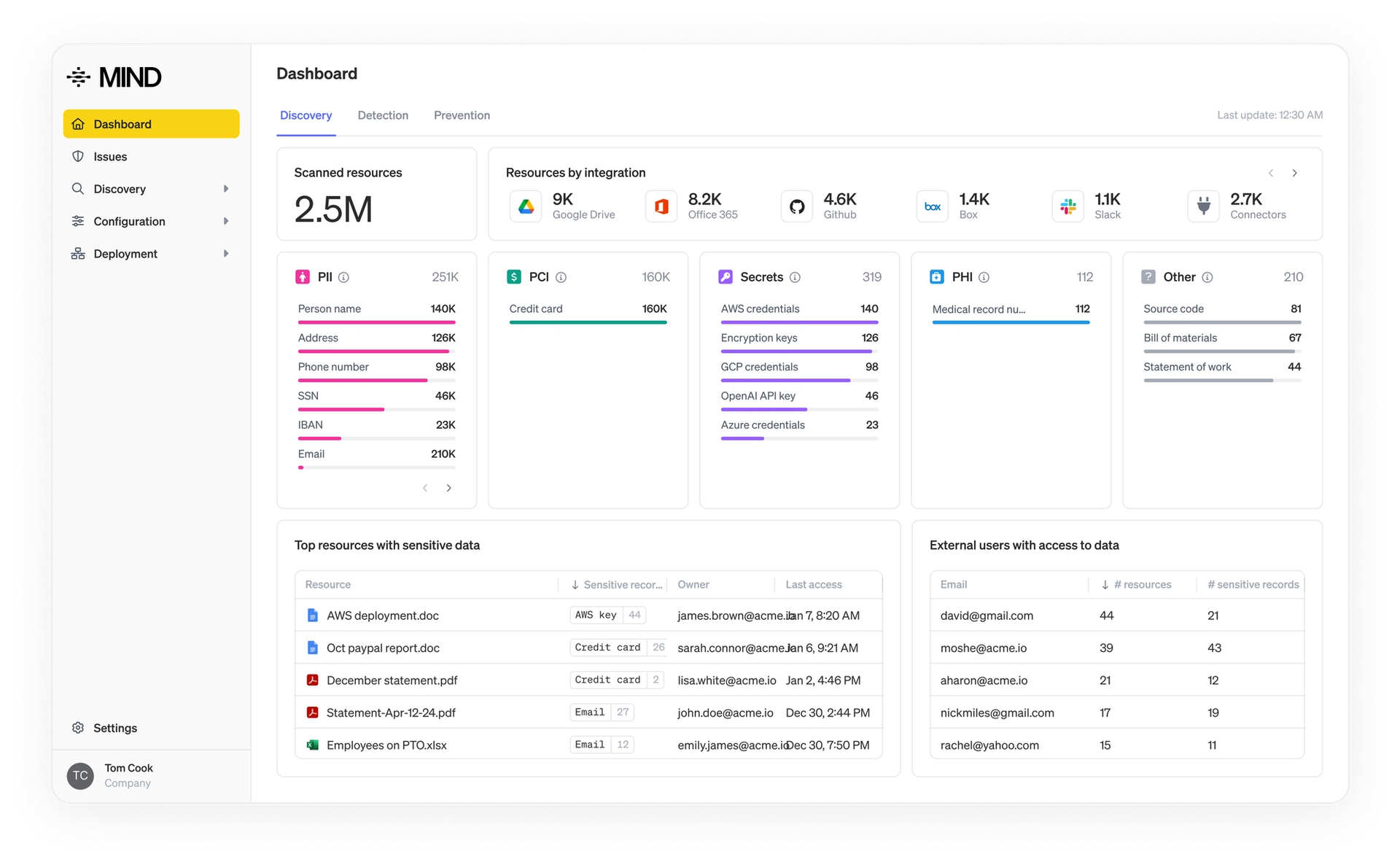
Modern data security rises or falls on the quality of its classification.
Modern data security rises or falls on the quality of its classification.
Classification Blog Series
- Classification done right: The key to scalable, effective data security
- 7 classification requirements for effective data security
- The Facebook ID problem breaking your DLP alerts
Without an accurate view of the diversity and scale of sensitive data across the whole organization, it can be nearly impossible to enforce any security controls. They become either too restrictive or miss large swaths of risky file movements. In distributed, cloud-first environments, classification is no longer a preliminary step. It needs to be a continuously operating system that informs every control decision downstream. Static labels and periodic scans can’t keep pace with how data is created, modified and moved today.
At MIND, we believe classification should accurately empower effective data security. This drives how our classification engine is architected, how it operates at scale and how it connects directly to enforcement mechanisms.
MIND's 7 data classification imperatives
Our approach is anchored in seven non-negotiable principles that guide every technical decision:
- Multi-layered by design to avoid single-model failure modes
- Complete coverage through full-content inspection, not sampling
- Real-time operation so classification scales with data movement
- Location-aware execution wherever data resides or flows
- Responsible AI applied deliberately and explainably
- Business-risk alignment beyond generic data types
- Direct enforcement coupling where classification drives control
1. Multi-layered classification is a technical necessity
No single technique can reliably classify all forms of sensitive data. This isn’t a philosophical stance. It’s a proven property of machine learning systems. The No Free Lunch Theorem shows that any model optimized for one class of problems will underperform on others.
MIND’s classification engine is intentionally multi-layered, combining complementary detection methods into a single decision framework:
- Structural analysis evaluates file type, encoding, schema and syntax to establish baseline understanding
- Statistical detection applies deterministic and probabilistic techniques to identify known sensitive patterns such as credentials, PII and PCI
- Semantic modeling uses small and large language models to interpret meaning, relationships and intent within unstructured content
- Contextual evaluation correlates content with user identity, access patterns, data movement and destination
Each layer independently contributes signal strength. Final classification decisions are derived from aggregated confidence, not single-model output. This design reduces false positives, improves recall and allows tuning without weakening overall accuracy.
2. Complete coverage requires full-content inspection
Sampling-based classification introduces unavoidable blind spots. Any system that inspects only a subset of files or partial content can’t guarantee coverage, especially in environments dominated by unstructured data.
MIND performs full-content inspection rather than probabilistic sampling. Files are scanned in their entirety, ensuring sensitive elements aren’t missed due to partial visibility. This approach is detailed and specific, but is made practical through:
- Parallelized scanning pipelines
- Content de-duplication and locality-sensitive hashing
- Incremental reclassification when files change
The result is comprehensive visibility without linear performance degradation. Scale is achieved through architectural efficiency, not reduced fidelity.
3. Classification must operate in real time
Data classification that runs on a schedule is already out of date. Files change. Content is appended, removed and transformed continuously. Security controls must react to the current state of data, not a historical snapshot.
MIND classifies data in real time, both at rest and in motion. When content changes, classification updates as it moves, automatically. When sensitive elements are added or removed, downstream controls respond accordingly.
This real-time model enables immediate enforcement actions such as blocking, alerting or coaching users at the moment risk is introduced, rather than after exposure has already occurred.
4. Location-aware classification reduces blind spots
Where classification occurs directly impacts accuracy and enforcement reliability. Centralized-only classification architectures introduce latency, visibility gaps and dependency on data movement.
MIND classifies data at its point of residence and as it moves through the environment. This includes:
- Endpoints
- SaaS and cloud storage platforms
- Source code repositories
- GenAI and Agentic AI interfaces
- On-premises file shares
- Messaging applications
- Wherever sensitive unstructured data resides
By classifying data where it lives, MIND maintains consistent understanding regardless of location or transport path. Classification metadata travels with the data, enabling uniform policy enforcement across heterogeneous environments.
5. Responsible AI enables precision at scale
AI is essential for understanding modern unstructured data, but unbounded AI introduces risk. MIND applies AI deliberately, using purpose-built models optimized for classification tasks rather than generic inference.
Our approach combines:
- Deterministic statistical methods where precision is required
- Small language models for constrained semantic interpretation
- Larger models only where contextual depth is necessary
All models are explainable, auditable and continuously evaluated. They are also proprietary to MIND and do not rely on publicly trained LLMs for effectiveness. AI is used to augment deterministic systems, not replace them. This ensures classification decisions remain defensible, tunable and aligned with business intent. In fact, our achievement of ISO 42001 certification demonstrates our commitment to responsible, explainable and auditable AI.
6. Classification must align to business risk, not just data types
Traditional classification systems stop at identifying data types. They answer what the data is, but not why it matters. That gap leads to overprotection in some areas and dangerous blind spots in others.
At MIND, classification is designed to reflect business risk. Sensitive data is evaluated in context of its purpose, ownership and potential impact if misused or exposed. This allows security teams to prioritize protection based on real-world consequences, not generic labels.
Additionally, MIND's classification can enhance other security measures and integrate with various tools for more effective security across the organization. For example, MIND can apply Microsoft Information Protection (MIP) labels to files, ensuring they are handled by Purview with the appropriate level of sensitivity within the Microsoft ecosystem.
By aligning classification to business risk, organizations gain clarity on what truly matters. Controls become proportional, decisions become defensible and security shifts from reactive compliance to intentional risk management.
7. Classification directly drives security controls
Classification without enforcement is observational. MIND treats classification as an active control plane.
Every classification decision feeds directly into data security actions, including:
- Blocking or allowing transfers
- Enforcing encryption or access restrictions
- Triggering user coaching or policy warnings
- Generating real-time alerts and automated remediation
There’s no abstraction layer between classification and control. This tight coupling ensures accuracy at the classification layer translates immediately into effective prevention.
Conclusion: classification as an operating system
At MIND, classification isn’t a feature. It’s an always-on system that continuously interprets data, context and risk. Multi-layered, real-time and location-aware classification enables security teams to move from reactive investigation to confident prevention.
Classification accurately empowers effective data security.
See MIND in action
To see how this architecture operates in real environments, get a demo and explore how MIND turns classification into control.
