






Classification isn't just a DLP step, it's the technical foundation for secure, scalable and context-aware data protection.
Classification isn't just a DLP step, it's the technical foundation for secure, scalable and context-aware data protection.
Classification Blog Series
- Classification done right: The key to scalable, effective data security
- 7 classification requirements for effective data security
- The Facebook ID problem breaking your DLP alerts
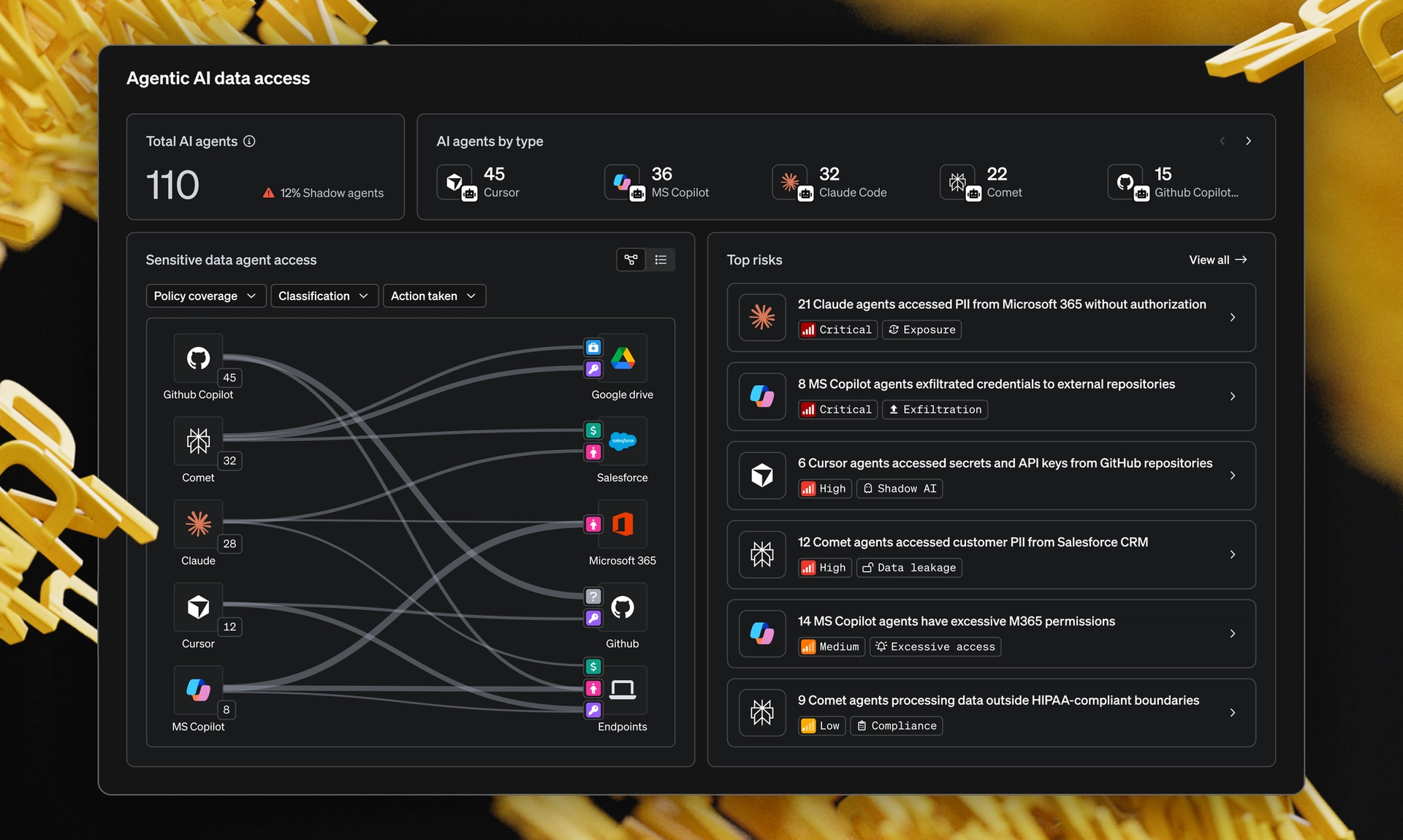
Classification is the practice of identifying and categorizing different types of data across an organization. This includes understanding what the data is, how it is used, where it resides and how sensitive it is. Done well, classification provides a reliable foundation for enforcing security policies, enabling data governance and reducing risk exposure.
Despite its importance, many organizations still lack a clear view of their data because their classification strategies are incomplete or overly reliant on narrow techniques. True classification must scale across environments and data types, adapting to both context and risk.
This isn’t about labeling a few files, it’s about building a consistent, organization-wide view of your data landscape, so you can take informed action to protect what matters most.
This piece breaks down the primary classification methods used in data security today and explains how MIND's Multi-Layer Classification approach categorizes and protects sensitive data across all environments.
Why do organizations need accurate classification?
Without accurate classification, DLP breaks down. A single mis-classification can set off a cascade of failures: a confidential file goes unflagged, an alert never fires, a user shares it externally and no one knows until it’s too late. Every policy, alert and enforcement action depends on it.
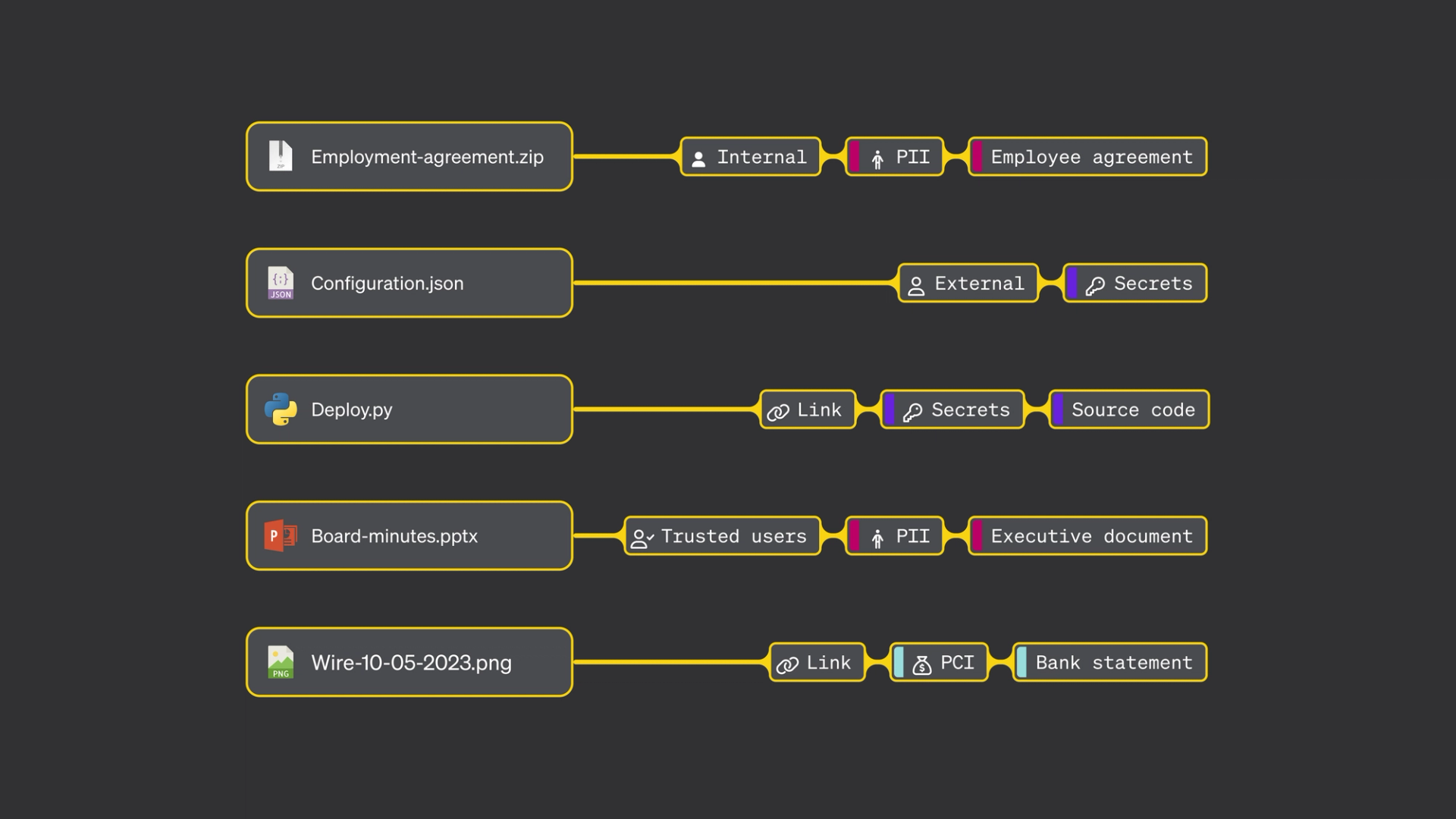
How do you find sensitive data?
Before data can be classified, it needs to be extracted, transformed and loaded (ETL) into a classification workflow.
Two common approaches dominate this phase:
- Sampling
Sampling takes a lighter-touch approach. It looks at a subset of files and often just portions of a file. This reduces workload, but it also reduces visibility, creating blindspots that allow sensitive data to slip through undetected. - Bit-by-Bit Scanning
This method processes every file in a given location, scanning each one in full. It’s accurate and thorough, but can be slower, resource-intensive and often impractical for modern environments or endpoints.
Most vendors pick one path or the other.
How is sensitive data classified?
After ETL, data is analyzed and classified using one or more techniques. These typically fall into three categories:
Rule-Based Techniques
These rely on known patterns and human-defined rules.
- Regular Expressions (RegEx): Detect known formats like SSNs or credit card numbers
- EDM (Exact Data Matching): Match against predefined values (e.g., a list of patient IDs)
- Policy-Based Classification: Use logic rules or boolean conditions to label content
Strength: High precision on known formats
Weakness: Easily bypassed, brittle, high false positives
Statistical & Probabilistic Techniques
These methods use math to infer likelihoods.
- Statistical Analysis: Estimate the probability that content belongs to a given category
- Predictive Models: Apply statistical features and learned behaviors to new data
- Hashing & Signature Matching: Check against known sensitive data fingerprints
Strength: Useful at scale, can flag novel instances
Weakness: Can miss nuanced or complex content
Semantic & Machine Learning Techniques
These systems learn patterns over time or from context.
- Vector Similarity (Categorization): Compare content to known examples via embeddings
- Machine Learning: Classify content based on trained models using labeled data
- SLMs/LLMs (Language Models): Understand data based on meaning, not just metadata
Strength: Adaptive, powerful on unstructured data
Weakness: Often expensive, opaque, and hard to tune
The problem with most vendors
Most classification engines today suffer from the same issue: they rely too heavily on a single method or rigid sequences for analysis.
- DSPM vendors lean heavily into visibility, but rarely go beyond structured data found in spreadsheets. For classification, they tend to rely on LLMs that do not scale and suffer from inconsistent results when asked the same question multiple times. These scale issues require them to default to a data sampling approach, limiting their effectiveness.
- Traditional DLP vendors rely on RegEx and rules, which has significant manual effort and staffing overhead. These techniques fail to interpret the intent or context behind the data which generate an enormous amount of false positive alerts. Some bolt on machine learning, but lack the architecture to apply it at scale, in context, or in real-time.
The result? Security teams get fragmented, inconsistent signals. Sensitive data goes undetected. Alerts pile up. And nobody trusts the output.
Classification, done poorly, becomes just another checkbox without delivering real security value.
The MIND approach: Multi-layered, context-aware, scalable
MIND reimagines classification from the ground up. It uses a multi-layered engine that applies the right technique in the right context, guided by environmental signals and risk posture.
MIND’s Differentiators:
- Risk-First Ingestion Strategy: MIND uses a bit-by-bit, full-file scanning approach that targets the sensitive data locations with the highest risk to the organization.
- Proprietary AI Models: MIND doesn’t outsource classification to public LLMs. We've built dozens of tailor-made Large & Small Language Models for the specific tasks required. This approach scales with your environment and understands the nuance of enterprise data
- Multi-Modal Analysis: Where it makes sense, we combine our proprietary trained LLMs, SLMs, EDM, RegEx pattern matching, statistical tests, vector similarity and proprietary ML for high-fidelity classification
- Beyond Structured Data: MIND is file type agnostic, allowing us to classify sensitive elements found in images, archives, documents, and rich media, not just .csvs and databases
- Autonomous Categorization: Instead of tagging individual data points, MIND categorizes entire datasets by meaning, usage, format and location, enabling policy by category (e.g., “PII in HR Reports shared externally”)
Why it matters
With a layered classification engine that scales across cloud, endpoint, on-premise file shares, email and GenAI apps, MIND reduces false positives, enhances the effectiveness of automated controls and builds lasting confidence in the integrity of data security workflows.
Instead of focusing on isolated identifiers like Social Security Numbers, MIND identifies entire categories of risk such as "regulated data shared in collaborative tools" or "sensitive contracts accessed by third parties."
When classification is done right, everything downstream, from detection to response, becomes more accurate, scalable and effective. That’s the argument we opened with, and it holds true across any environment, industry or data type. MIND’s layered, risk-aware classification engine was built to meet that standard.
If you're evaluating how to improve fidelity, coverage and automation in your data protection program, our team is available to explore how this approach fits your environment.


